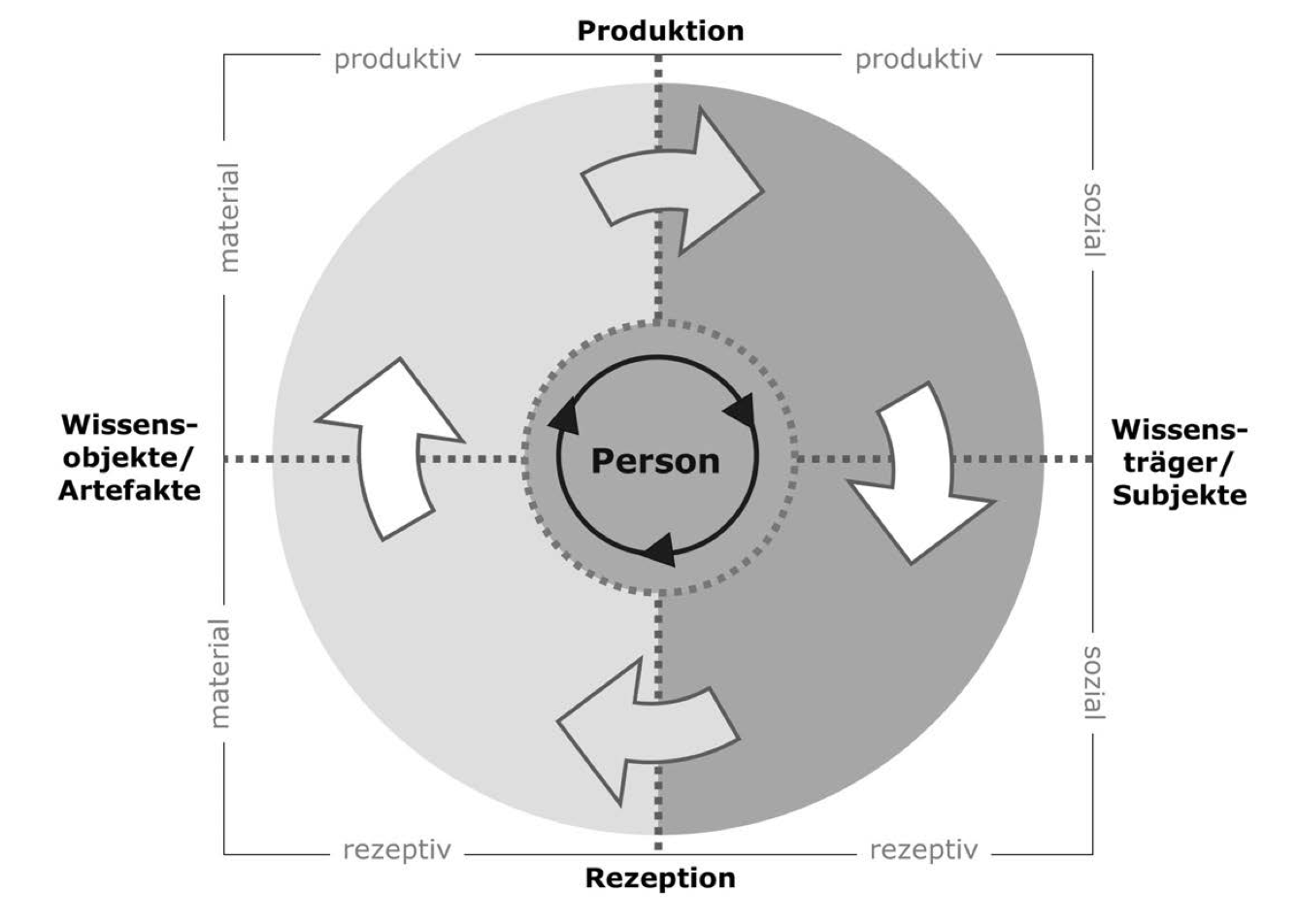
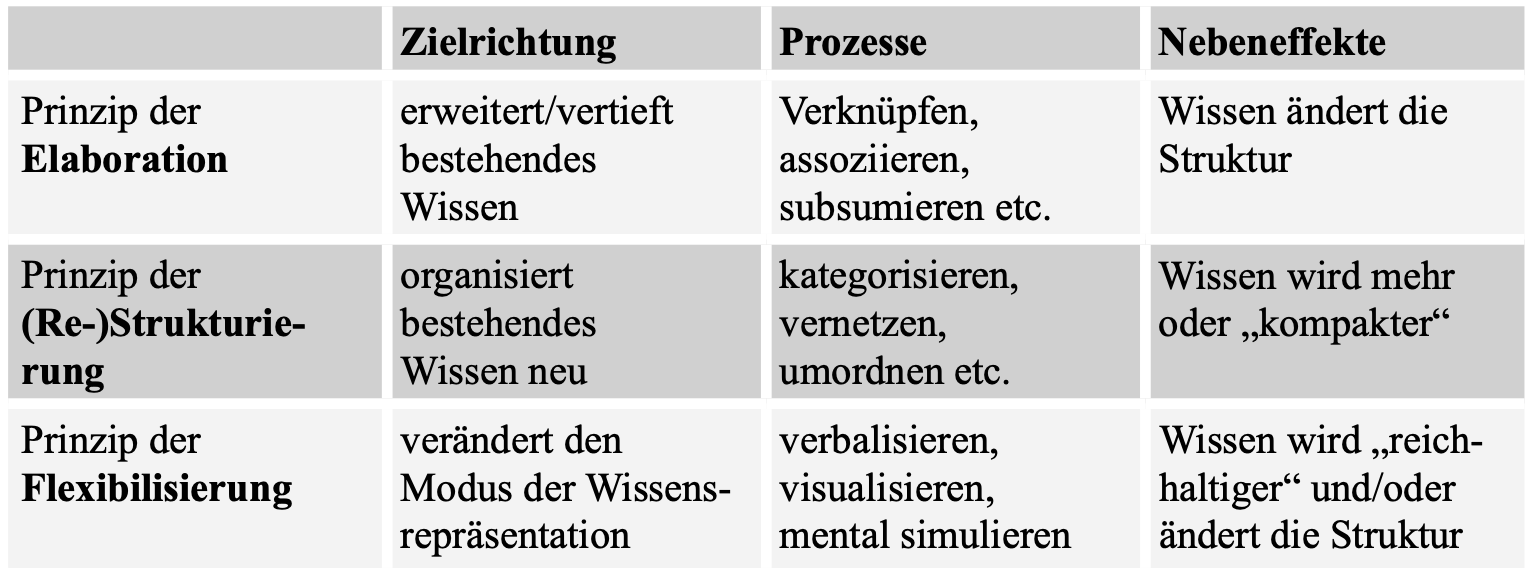
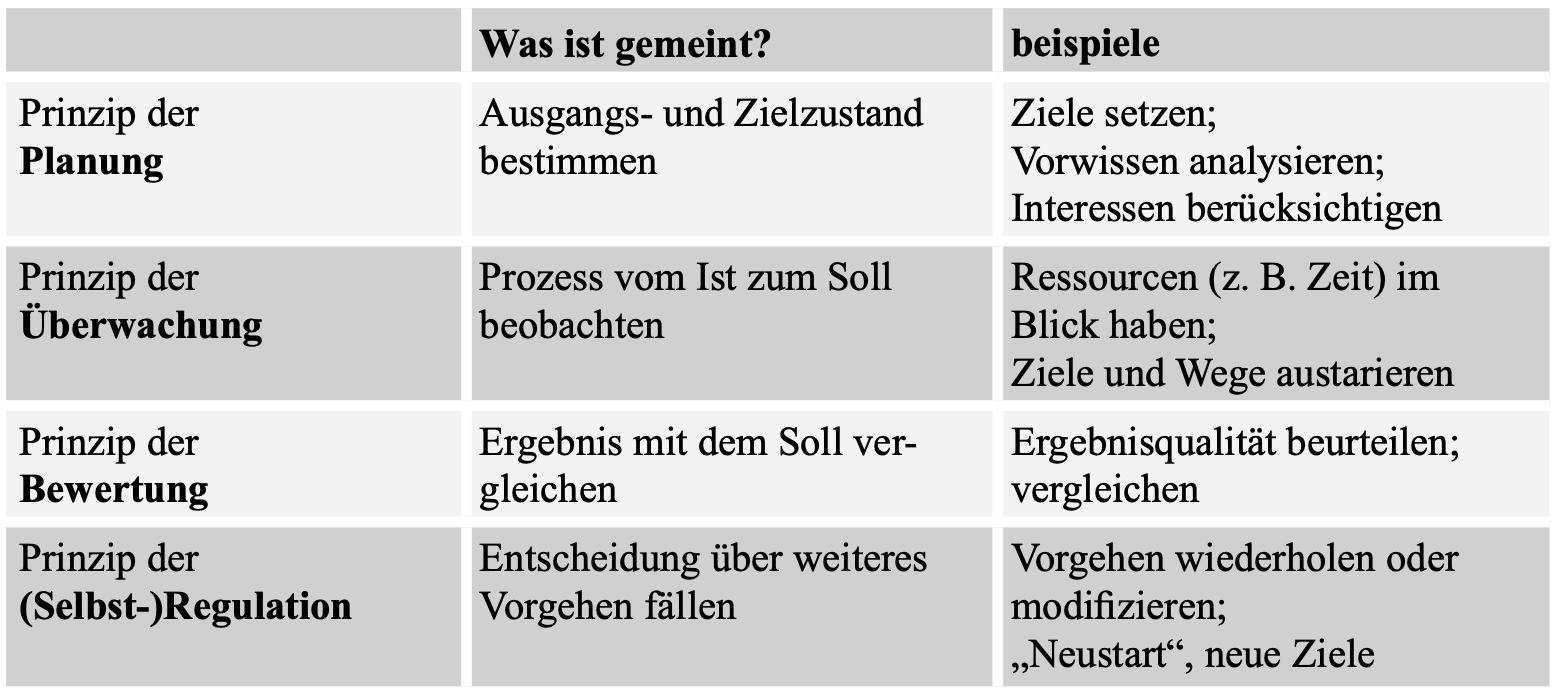
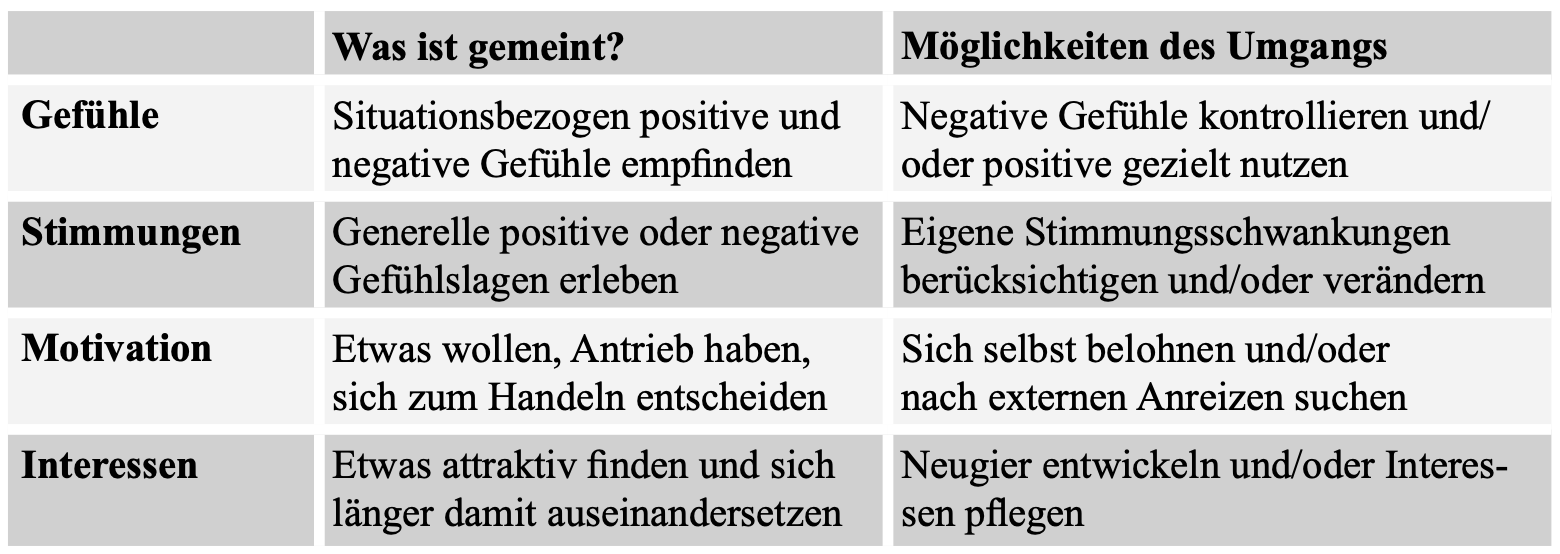
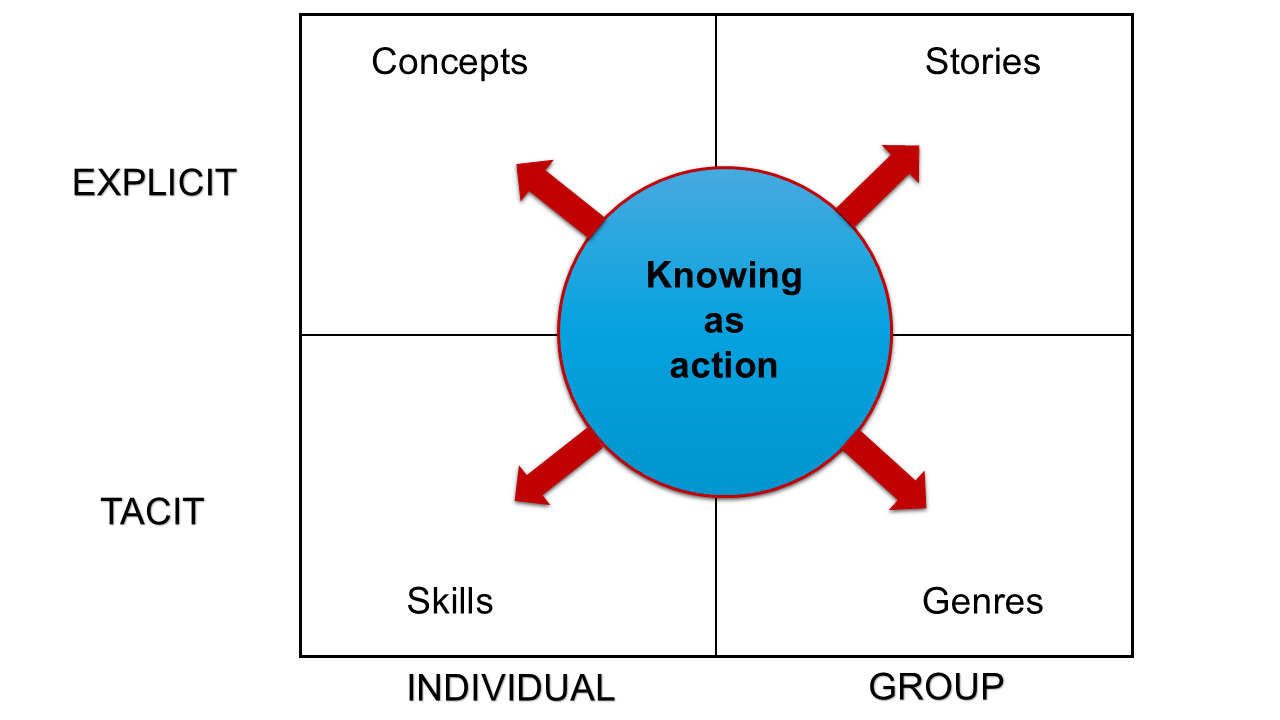
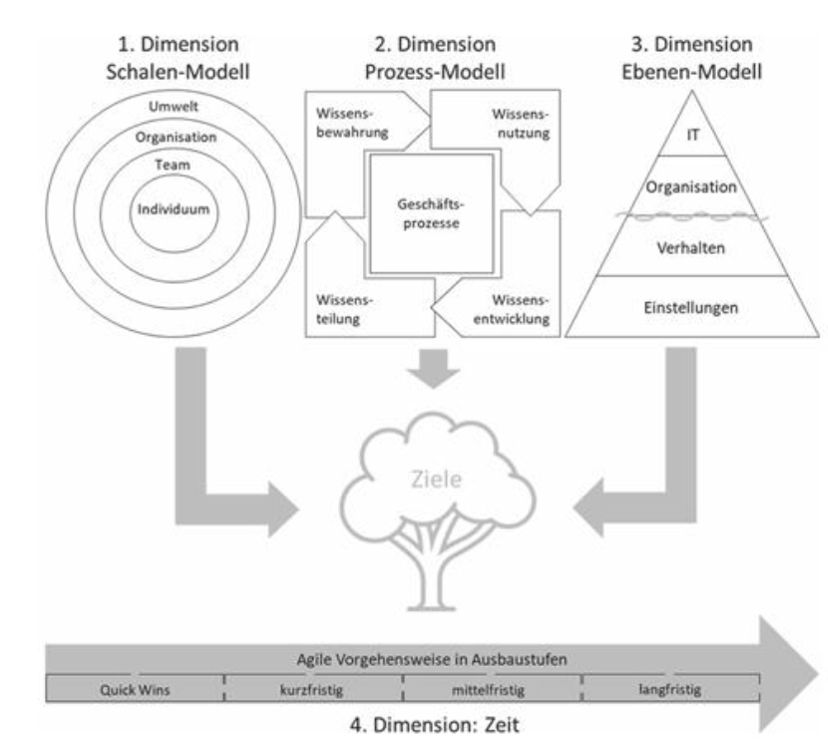
Es gibt im Wissensmanagement zahlreiche Modelle. Warum ist es auch jenseits einer eher akademisch-theoretischen Beschäftigung mit Wissensmanagement nützlich, sich mit einem oder mehreren Modellen auseinanderzusetzen?
- Ein Modell ist ein vereinfachtes Abbild der Realität und kann daher komplexe Sachverhalte (Was ist Wissensmanagement?) deutlich machen.
- Es kann dabei helfen, ein gemeinsames Verständnis – im WM-Projektteam, in der Organisation, auf Ebene der Entscheider – herzustellen.
- Es kann Orientierung bieten (klare Struktur o.ä.).
- Es kann dabei helfen, sich auf Wesentliches zu konzentrieren, z. B. in der Entwicklung eines WM-Konzepts.
- Es kann konkret bei der Stärken-Schwächen-Analyse unterstützen.
- Es kann dabei helfen, das eigene spezifische Wissensmanagement für andere nachvollziehbar darzustellen.
- Es kann dabei helfen, Wissensmanagement an andere Themen in der Organisation anzubinden, z. B. Prozessmanagement, Qualitätsmanagement, Innovationsmanagement.
Weitere grundlegende Überlegungen zu Nutzen, aber auch Grenzen von Modellen im Wissensmanagement bietet das Kapitel 4.1. in diesem Studientext von Gabi Reinmann.
Im Folgenden werden einige ausgewählte Wissensmanagement-Modelle näher erläutert:
- Bausteine-Modell nach Probst
- Potsdamer Modell nach Gronau
- Wissenstreppe nach North
- Modell der Gesellschaft für Wissensmanagement (GfWM-Modell)
- Münchner Modell nach Reinmann/Mandl
- SECI-Modell oder Wissensspirale nach Nonaka und Takeuchi
- MOT – Modell (bzw. TOM)
- 3-Säulen-Modell
- Wissensgarten nach Vollmar
- WM4-Modell
- Bridging Epistemology Framework
- Persönliches Wissensmanagement Modell
Denkaufgabe:
Nachdem Sie sich mit den verschiedenen Modellen beschäftigt haben, überlegen Sie:
- Worin unterscheiden / ähneln sich die vorgestellten Modelle?
- Wo liegen deren jeweilige Stärken und Schwächen?
- Welches dieser Modelle würde für meinen Kontext / meine Organisation am besten passen? Warum?
In der Live Session des WMOOC 2016 hat Dr. Angelika Mittelmann unter anderem auch über Ihre eigenen Praxiserfahrungen bei der Einführung von Wissensmanagement gesprochen und darüber, inwieweit Wissensmanagement-Modelle hier von Nutzen sein können. Die relevanteste Passage zum Einsatz von Modellen findet sich ab Min 4:07 bis ca. Min 11:35 im Video (Gesamtdauer 51:01 Min):
Kommentare/Hinweise:
Ergänzungs- o. Änderungsvorschläge hier in der XING-Diskussion, oder (notfalls, wenn kein XING-Account gewünscht) als eMail (unbedingt mit dieser URL) an uns Autoren (Gabriele Vollmar und/oder Dirk Liesch).
Ergänzungs- o. Änderungsvorschläge hier in der XING-Diskussion, oder (notfalls, wenn kein XING-Account gewünscht) als eMail (unbedingt mit dieser URL) an uns Autoren (Gabriele Vollmar und/oder Dirk Liesch).