
- Wissens-Datenbanken, Wissenspools
- „Service-Desk“-, „Help-Desk“, „Hotline“- und „Ticket – Systeme“ bzw. „Use Case“ – Verwaltung
- Customer Relation Management – Systeme (CRM)
behandeln wir hier zusammengefasst, weil es DIE „Datenbank“ – Anwendung für einen Wissenspool nicht gibt, sondern „Wissens-Sammlungen“, die mehr oder weniger strukturiert, geordnet und/oder mit festen Workflows vebunden sind. Je strukturierter, geordneter, definierter/festgelegter, prozess- und workflowoptimierter eine Wissenssammlung ist, desto stärker erinnert die Anwendung an eine „Wissens-Datenbank“, da Datenbanken für strukturierte, wohldefinierte Informationen und Daten stehen.
Technisch sind heute selbst viele Wiki-, Blog-, Microblogging Anwendungen ganz oder zu einem großen Teil Datenbank-Anwendungen.
Deshalb wird hier auf strukturierte Wissenspools, Help-Desk – und CRM – Anwendungen eingegangen.
Prinzipiell gibt es immer die Möglichkeit komplexe Informationen „unstrukturiert“ (z.B. Dokumenten-Sammlung) oder strukturiert (z.B. Datensätze in einer Datenbank) abzulegen. Beides hat Vor- und Nachteile. Über die strukturierte Variante ist es einfacher feste Workflows und Prozesse zu legen und diese auch mit bestehenden Unternehmensprozessen (Stichwort: Prozessmanagement) zu koppeln. Inwieweit in die jeweilige Implementierung tatsächlich eine Datenbank involviert ist, ist zweitrangig.
Welche Aspekte sind für eine Wissensdatenbank / einen Wissenspool zu beachten?
Das hängt von der Größe, Branche und Internationalität der Organisation ab. Die Grafik zeigt einige der Dimensionen:
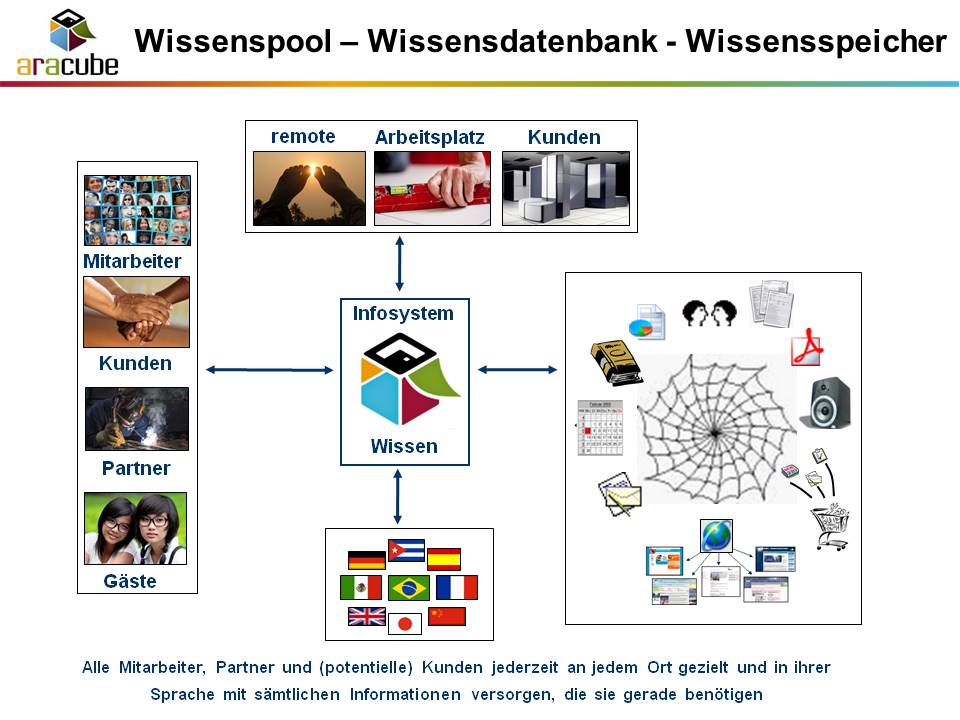
Die Darstellung bezieht sich auf einige Fragenkomplexe, die möglichst vor dem Aufbau eines Wissenspools zu beantworten sind:
- Welche Inhalte, welche Medien und in welchem Umfang sollen wie enthalten sein? Wie erfolgen Strukturierung, Pflege, Nutzung, Administration und Sicherstellung der Aktualität?
- Welche Nutzergruppen (Stake Holder) sollen in welcher Form und nach welchen Berechtigungen auf das „Wissen“ Zugriff haben? Wie sehen Rechte- und Sicherheitsanforderungen für die unterschiedlichen Informationen aus?
- Wie und von wo aus soll der Zugriff erfolgen können, lesend, schreibend (anlegen, ändern, löschen)? Von welchen Endgeräten und aus welchen Netzen sollen welche Zugriffe möglich sein?
- Wie wird sichergestellt, dass jede(r) genau die Informationen erhält, die gerade benötigt werden, die „richtigen“ Informationen und nicht mehr (Stichwort: Informationsüberflutung)?
- Welche Sprachversionen der Informationen (und des Benutzerinterfaces) sind ggf. erforderlich und wie werden die Übersetzungen und deren Aktualität gemanaged?
- Wie werden Tochtergesellschaften u.a. angebunden, durch Online-Zugriff auf das zentrale System, oder über lokale „Clustersysteme“? Reichen die Bandbreiten für die angedachten Nutzungen? Wie werden ggf. die Inhalte der „Clustersysteme“ abgeglichen (aktuell gehalten)? Ist dies vollständig oder teilweise (partiell) erforderlich?
Für internationale Konzerne mit Einsatzgebieten ohne sinnvolle Internetanbindung und mit wichtigen vertraulichen Informationen ist die Konzeption und Realisierung deutlich komplexer als für einen lokalen Handwerksbetrieb mit 10 Mitarbeitern, der hauptsächlich in seiner Region tätig ist.
Beispiel für die Gruppe der Helpdesk-Systeme:
- Lernen Sie JIRA Service Desk kennen (2:35 min, Achtung: Produktvorstellung!!!, SEIBERTMEDIA)
Praxisbeispiel(e)
Im folgenden Video wird die Zielsetzung des Einsatzes einer Wissensdatenbank im Unternehmen vorgestellt: „Die Vorteile von Wissensmanagement im Unternehmen“ (2:50 min, Meusburger Georg GmbH & Co KG)
Kommentare/Hinweise:
Wir freuen uns über Ergänzungs- oder Änderungsvorschläge. Gerne per eMail (unbedingt mit dieser URL) an uns Autoren (Gabriele Vollmar und/oder Dirk Liesch).